Автор:
Автор: 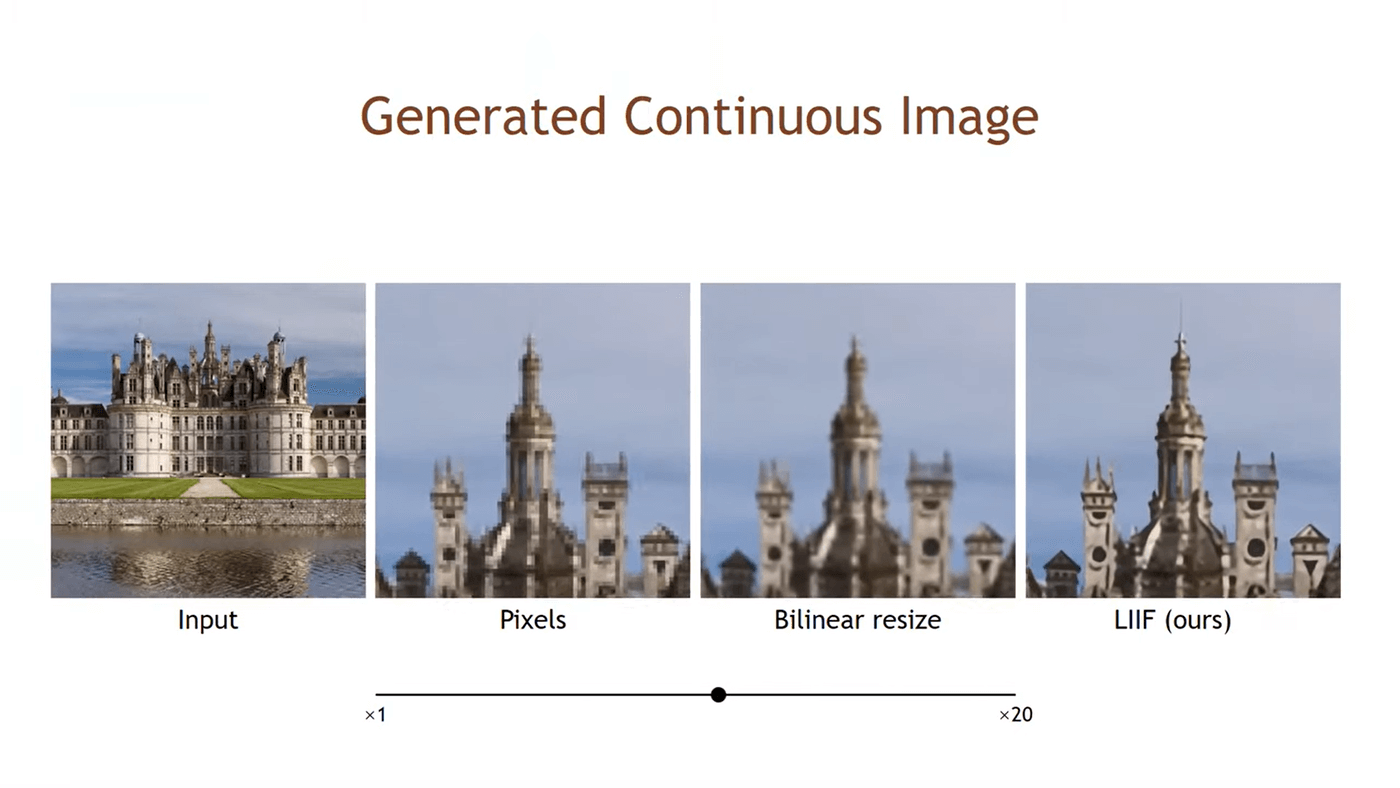
В сериалах и фильмах про полицию часто показывают, как из видео и фотографий низкого качества удаётся получить детальное изображение человека или номерного знака автомобиля. Неизвестно, были ли в руках у спецслужб такие технологии ранее, но с появлением нейросетей это стало реальностью. Исследователи из Калифорнийского университета в Сан-Диего и NVIDIA наглядно продемонстрировали работу такого алгоритма.
Разработанная нейросеть умеет кодировать растровое изображение сверхнизкого разрешения во вполне качественную картинку. В отличие от уже существующих алгоритмов, способных повышать разрешение, новый алгоритм способен работать не только с фиксированным разрешением, но и с разными масштабами без чётких ограничений по разрешению.
Одним из главных достижений разработчиков стало то, что для улучшения качества исходного изображения нейросеть анализирует и описывает не всю картину целиком, а разные её фрагменты. Указывается, что при получении координат определённого места на изображении соответствующая локальная функция использует кодированное представление признаков на окружающей области и воссоздаёт предполагаемые пиксели. В результате это позволяет рендерить изображение произвольного разрешения.
Для обучения нейросети использовался датасет DIV2K, состоящий из тысячи фотографий в разрешении 2K и уменьшенных в два, три и четыре раза версий. Перед алгоритмом стояла задача сначала уменьшить разрешение изображения, а затем вернуть его в исходное, полностью восстановив оригинал.
Примеры работы нейросети представлены в видео: