Автор:
Автор: 
Кирилл Серых, автор блога «Laptop Coach», дата-сайентист в Sportec Solutions и тренер юношеской команды U17 в берлинской «Тасмании», рассказывает, какое значение приобрела аналитика в индустрии футбола, как собираются и анализируются данные по игрокам и событиям на поле, а также о навыках, необходимых дата-сайентисту или аналитику для работы с футбольной командой. А Владимир Герингер, автор блога «Футбол в цифрах» и выпускник курса «Data Scientist» образовательной компании «Нетология» делится своим опытом работы с данными в своём проекте.
Какую пользу приносит аналитика данных футбольной команде и почему дата-сайентистов держат в секрете
Кирилл Серых:
Анализ данных с каждым годом становится всё более неотъемлемой частью футбола. Так, довольно весомый вклад в победы «Ливерпуля» в 2018-2020 годах сыграли не только тренерское мастерство и новаторство Юргена Клоппа, но и отличная работа Data Science отдела под руководством Иана Грэма. Грэм сумел найти общий язык с тренерским штабом и сыграть большую роль в формировании команды и анализе игры на протяжении последних сезонов.
Классический подход, когда матч воспринимается через призму видения тренера или скаута, зачастую упускает многие вещи, происходящие на поле и является всё же субъективной оценкой. Анализ данных же призван дополнить эту оценку и дать объективные выводы и по каждому игроку, и по командным действиям в целом.
Многие команды не выносят на широкую публику информацию об устройстве своих отделов по Data Science. Например, в бундеслиге Германии играет 18 команд. И мне известны всего 6 из них, в которых есть хотя бы один Data Scientist. В Английской Премьер лиге (АПЛ) и Чемпионшипе (2 главные лиги Англии) такие отделы есть практически у всех. Поэтому то, насколько распространена аналитика в футболе, сильно зависит от страны, футбольного клуба или чемпионата.
«Что касается ситуации в России, то говорить о неком институте Data Science или отраслевых стандартах аналитики в российском футболе пока не приходится. Тем не менее, Data Science и анализ данных – это одна из самых горячих и бурно развивающихся индустрий 21 века, инструменты которой в большей степени применяются в бизнесе. Футбол – это тоже своего рода бизнес, и не маленький. Поэтому клубы безусловно будут смотреть в сторону современных подходов к анализу данных, накапливать экспертизу, выстраивать бизнес-процессы в этом направлении», — рассказывает Владимир Герингер.
Такая секретность связана с тем, что детальный анализ данных даёт возможность получить преимущество команде в том или ином аспекте. Как раз одной из причин успеха «Ливерпуля» была разработка и верное использование математических моделей игры, опережающих на тот момент практически все существующие. Например, они внесли большой вклад в их скаутинг – аналитики «Ливерпуля» подобрали максимально подходящих Клоппу по стилю и принципам игры игроков, что помогло построить одну из лучших команд 2010-ых.
Данные дали «Ливерпулю» конкурентное преимущество несколько лет назад, и чтобы не отставать от лидеров, клубы выделяют все большие бюджеты на data-related сотрудников. Это конкурентное преимущество крайне важно в спорте.
Можно провести параллель финала ЧМ-1952, где играли Германия и Венгрия – простой пример с бутсами. Венгры подходили к матчу в статусе фаворита, и несмотря на счёт 2:2 к середине второго тайма, доминировали в матче. Но в это время пошёл дождь, и экипировщик сборной ФРГ Ади Дасслер (один из основателей фирмы Adidas) настоял поменять обувь и надеть бутсы с более длинными шипами. Это позволило им меньше скользить на поле, более эффективно участвовать в единоборствах и в итоге выиграть 3:2, забив в конце матча. После этого обувь со сменными шипами стала стандартом индустрии на следующие десятилетия. Поэтому каждый раз, когда появляется инновация, дающая преимущество, глупо не использовать её в команде.
Сколько аналитиков работает на команду и какие данные они ищут
Кирилл Серых:
Количество аналитиков в команде варьируется от страны, уровня и финансовых возможностей клуба. Например, в «Барселоне» весь отдел, связанный с обработкой и анализом данных, включает 17 человек. Сюда входят глава отдела аналитики, 6 дата-сайентистов, которые занимаются математическим моделированием; 9 аналитиков данных, которые интерпретируют данные и на их основе предлагают или вносят правки в модели (параллельно эти же люди могут заниматься анализом видео и тактическими наработками); 1 IT-специалист (IT-администратор), ответственный за техническую инфраструктуру.
Такой мощный состав отдела аналитики – редкость для большинства даже крупных футбольных клубов. Однако, по моим наблюдениям, условный футбольный клуб из топ-7 чемпионатов в худшем случае имеет хотя бы одного аналитика. Конечно, это экстремальный случай, ведь человеку приходится совмещать анализ данных с тактическими разборами и подготовкой видео, но всё же это минимальная база. Со временем её можно наращивать за счёт большего количества аналитиков и дата-сайентистов, собственных технологических решений и инфраструктуры.
Что конкретно делают дата-сайентисты и аналитики
Кирилл Серых:
Допустим, перед отделом аналитики стоит задача проанализировать игру команды соперника. Для этого просматриваются последние несколько игр – от трёх и более в зависимости от размера отдела и технологических решений, имеющихся в клубе. В процессе аналитики изучают, какие тактические расстановки и игровые наработки использовались соперником.
Общаясь с аналитиками, дата-сайентист может получить задачу на поиск определённых особенностей построения игры. Например, найти все моменты, когда отдается передача форварду за спину или атака проходит после проникающей передачи из глубины через один из флангов. Подобные оговоренные моменты находятся, сохраняются в виде xml-файлов и интегрируются в платформы, используемые аналитиками для анализа видео. Это очень сильно экономит время аналитикам.
Также дата-сайентиста могут попросить найти закономерности в действиях игроков и команды в целом: построить карты кластеров пасов, определить тактические схемы команды и их изменения во время игры или проанализировать механизм принятия решений вратарем в ситуациях 1-на-1.
Помимо этого, дата-сайентист должен анализировать и внедрять новые метрики, позволяющие сделать более детальный анализ. На практике их слишком много, и чтобы перечислить их все, понадобится написать отдельную статью. Самая простая и известная – xG (expected goals), оценивает вероятность гола после удара. Например, Лионель Месси бьёт по воротам соперника с 25 метров левой ногой под углом к воротам в 45 градусов, в радиусе 3 метров его окружают три защитника, а вратарь стоит на расстоянии 17 метров от игрока. Какова вероятность, что Месси забьёт гол?
Одна из самых продвинутых метрик в футбольной аналитике, внедрённая в футбол из NBA аналитическим отделом «Барселоны», – это EPV (Expected Possession Value) или ожидаемая ценность владения. Это оценка того, забьёт ли команда следующий гол. При оценке учитывается информация о расположении игроков в данном моменте. Предполагается, что у игрока есть три действия, которые можно совершить с мячом – провести мяч в какую-либо точку поля, отдать пас или ударить. Используя различные математические модели и модели машинного обучения как для расчёта факторов, влияющих на полезность принимаемого решения (например, уровень оказываемого прессинга на игрока с мячом), так и вероятности этих трёх действий, даётся оценка того, забьёт ли гол та или иная команда.
Кто и как собирает данные об игроках и событиях матча
Кирилл Серых:
Сейчас все футбольные данные можно грубо разделить на 2 вида – трекинговые и событийные. Трекинг – это координаты всех игроков на футбольном поле, собранные с частотой от 10 до 50 кадров (строк с координатами) в секунду. Эти данные собираются либо с помощью сертифицированных GPS-датчиков, либо на стадионах ставят специальное оборудование – камеры высокого качества, картинка с которых обрабатывается алгоритмами распознавания объектов, после чего выдаются координаты игроков и мяча.
Во втором случае футбольная лига даёт специальное разрешение на использование этого оборудования во время игры. Например, в Германии обработкой видео и сбором трекинговых данных занимается шведская компания ChyronHego, а дочерняя компания DFL (Немецкая Футбольная Лига, аналог Российской Премьер-Лиги) Sportec Solutions занимается их анализом по играм 1 и 2 Бундеслиги. Также Sportec Solutions собирает событийные данные – информацию о каждом событии, происходящем на поле (пас, удар, перехват мяча, гол). Этим вручную занимается операционный отдел. После этого аналитики оценивают полученные результаты и дают тренеру и игрокам рекомендации для повышения эффективности игры.
Способ сбора данных зависит от конкретного футбольного клуба. В Германии клубы 1 и 2 Бундеслиги получают доступ к данным Sportec Solutions по умолчанию. Кроме того, компания предлагает несколько BI-приложений, позволяющих получать и анализировать информацию как в режиме реального времени, так и до и после матча.
Но информацию по другим лигам, что может быть полезно в том же скаутинге, клубам приходится покупать у сторонних компаний – дата-провайдеров. Помимо доступа к сырым данным эти компании предлагают специальный софт, позволяющий анализировать уже агрегированную статистику и использовать анализ видео. Клубы не всегда раскрывают информацию о том, чьими клиентами они являются.
Некоторые клубы, как тот же «Ливерпуль» пытаются собирать данные самостоятельно: мерсисайдцы купили французский стартап SkillCorner, чей главный продукт – сбор трекинговых данных по бродкастингу. Однако их методика измерения не даёт 100% точности, потому что ТВ-картинка не охватывает большую часть поля и игроков и полученных данных пока что не хватит, чтобы качественно откалибровать модели экстраполяции движения игроков и мяча. Клуб довольно долго не давал информацию о покупке стартапа, хотя в индустрии ходили слухи, что они хотят собрать как можно больше трекинговых данных по разным лигам своими силами.
Также буквально на днях один из провайдеров данных StatsBomb анонсировал релиз StatsBomb360 – более расширенный набор событийных данных, включающий не только координаты игроков, участвующих в событии, но и координаты всех игроков на поле в этот момент. По утверждению компании, этот набор даёт от 85 до 90% информации от полного сета трекинговых данных. На мой взгляд, это достаточно спорное утверждение, требующее детального рассмотрения этих данных. Однако на данный момент это действительно большой шаг внутри индустрии. Неудивительно, что одним из их первых клиентов стал «Ливерпуль».
Качество и объём покупаемых данных зависит от бюджетов клубов на подобные расходы. Их стоимость варьируется в зависимости от чемпионата и качества данных. Например, два года назад я покупал данные у компании WyScout по голландской лиге, и API-доступ к событийным данным стоил 3600 евро в год. А покупка данных у таких компаний как Opta Pro может стоить от 60000 до 80000 евро в год.
«В России тоже существуют аналитические компании и агентства, которые предоставляют разрозненные данные для футбольных клубов, игроков и тренеров. В основном это данные о здоровье и физической форме игроков или описывающие индивидуальные технико-тактические действия. Чаще всего речь идёт о простых таблицах Excel, куда селекционеры, скауты и аналитики вносят информацию об игроках, которых они посмотрели по метрикам. А кто-то до сих пор делает записи в тетрадь», — говорит Владимир Герингер.
В целом по индустрии собирать унифицированные качественные данные пока ещё сложно. Те же события по одному матчу у разных провайдеров могут иметь расхождения в несколько метров и секунд в зависимости от компании. Собрать унифицированные трекинговые данные ещё сложнее, как минимум, с юридической точки зрения. Например, в Германии только ChyronHego имеет доступ к установке своего оборудования, и данные по Бундеслигам доступны только немецким клубам. Если даже на это закрыть глаза, то так как объём трекинговых данных для одного матча (3,6 миллиона строк для частоты 25 кадров в секунду против 1600-1800 событий за матч в среднем), то «шум» или погрешности этих данных гораздо сложнее устранить. И нужно не забывать о том, что трекинг собирается разными методами в разных лигах.
Лысая голова вместо мяча или почему искусственный интеллект не всесилен
Кирилл Серых:
Мне кажется, что сейчас проще всего зайти в индустрию футбола со стороны компьютерного зрения (computer vision), а именно для футбола это технологии распознавания объектов на видео. Большинство компаний сейчас даёт доступ только к двум координатам. То есть футбольное поле представляется двумерным объектом, по которому передвигаются точки. Конечно, было бы интересно получить третью координату – как высоко летит мяч, каким было положение тела игрока в пространстве во время действия. Это сложно в реализации, и качество зачастую очень низкое. Хотя и Sportec Solutions, и Statsbomb всё же имеют эту третью координату как минимум для мяча.
Не так давно во время футбольного матча искусственный интеллект, встроенный в камеры распознавания объектов, принял лысую голову арбитра за мяч. Это привело к тому, что зрители в реальном времени всю игру наблюдали за передвижением не мяча по полю, а арбитром, который бегал в нескольких метрах от происходящего.
Дело в том, что во время игры оборудование для сбора данных предоставляется разными компаниями, и качество этого оборудования тоже разное. В данном случае матч снимали на очень простые камеры Veo, состоящих всего из двух линз: одна смотрит в левую часть поля, другая – в правую. Далее камера синхронизирует две полученные картинки, и получается панорама происходящего. Так как качество оборудования хуже по сравнению с тем, которое используют во время серьёзных чемпионатов, и камер было всего две, то произошел подобный казус.
Для сравнения, в Германии ChyronHego ставит от 16 до 20 камер на каждый обслуживаемый стадион. Такое количество оборудования обеспечивает гораздо более высокую точность картинки.
Какие инструменты необходимы специалисту по аналитике
Кирилл Серых:
Дата-сайентисту для работы нужны навыки программирования в Python. Он применяется в построении всех моделей, связанных с машинным обучением. Это основной язык, на котором пишут алгоритмы большинство дата-сайентистов. Python также используется в подготовке дашбордов с помощью Dash. Хотя некоторые специалисты предпочитают программировать приложения в JavaScript.
Python также очень часто используется при визуализации данных. Но иногда приходится применять JavaScript, так как некоторые визуализации проще строить в библиотеке d3. Иногда Python’y предпочитают язык R, так как большинство библиотек с открытым доступом к футбольным данным адаптированы как под Python, так и под R. Выбор одного из этих двух языков – вопрос индивидуальный. Например, 95% своего времени я работаю в Python, а R и JavaScript использую для небольших задач.
Для работы с базами данных специалисту требуется также знание SQL и небольшие навыки работы с API – понимать структуры запросов / ответов, разницу в методах доступа (get, post, delete) и прочие базовые вещи для получения доступа к информации. Опыт работы с облачными системами (AWS, GCP) также будет не лишним, так как всё большее количество клубов переходит на хранение информации и построение пайплайнов в этих сервисах.
Как происходит работа с данными на примере проекта «Футбол в цифрах»
Владимир Герингер:
«Футбол в цифрах» – это некоммерческий проект трёх энтузиастов, неравнодушных к футболу и аналитике данных. Мы собираем данные из открытых источников о различных турнирах и формируем по ним единую базу данных.
В российском футболе давно наметился негативный тренд – уже не первый сезон наши команды не могут показать хороших результатов в еврокубках, а сборная с трудом зарабатывает очки в международных соревнованиях. Мы считаем, что все проблемы начинаются ещё на этапе воспитания молодых футболистов. Так у нас родилась идея собирать и анализировать данные по юношеской футбольной лиге (ЮФЛ), чтобы понять, в каком состоянии находится наш юношеский и молодёжный футбол – основные стадии становления будущих профессиональных футболистов.
Проанализировав данные в комплексе, мы хотим понять основные закономерности и реалии подготовки подрастающего поколения, а самое главное – выработать эффективные решения для развития и улучшения игры российских команд.
Как мы работаем с данными
Владимир Герингер:
Обычная цепочка работы с данными: сбор данных –> обработка данных –> создание базы данных (Vertica, MySql и др.) –> BI-оболочка (Tableau, Power BI, Qlik) –> Machine Learning (Python, R).
Одним из подходов, который я и моя команда используем в проекте, является data-blending – мы объединяем данные из различных источников, чтобы собрать максимальный набор метрик и измерений для построения сквозной аналитики. То есть собираем данные из различных открытых источников и агрегируем их в единую базу данных, которая является ядром нашего проекта.
После сбора мы обрабатываем и очищаем данные. Далее они загружаются на сервер, и мы визуализируем эти данные в интуитивно понятной и удобной оболочке Tableau. Только после этого происходит обучение математических моделей для поиска ответов на разные вопросы и проверки гипотез.
На текущий момент мы собираем и обрабатываем данные о результатах и расширенной статистике матчей, антропометрические данные футболистов, индивидуальные технико-тактические действия игроков, плюс некую персонализированную информацию по клубам и футболистам, которая позволяет дополнить и расширить возможности для аналитики.
На этапе сбора и парсинга данных мы используем Python, в частности библиотеки BeautifulSoup и Selenium:
Далее с помощью Pandas формируем данные в файл определённого формата и структуры, которая поможет в дальнейшем рассчитать необходимые метрики:
В итоге мы получаем подготовленную колоночно-строчную таблицу, на основании которой можно визуализировать данные или обучать модели.
Сейчас наша база данных состоит из 65 столбцов и более 3 млн. строк – здесь собраны данные, начиная с 2015 года по Лиге Чемпионов, Лиге Европы, российской премьер лиге (РПЛ), молодёжной премьер-лиге (МРПЛ) и юношеской футбольной лиге (ЮФЛ). А также английской АПЛ, французской Лиги-1, итальянской Серии А, немецкой бундеслиги, испанской Примере. В базе данных содержится подробная информация и система метрик по более чем 18 000 футболистов, 1 800 тренеров и сотрудников штабов команд и 650 судей.
Такой подход к работе с данными позволяет сравнивать чемпионаты и страны между собой и в целом понимать, на каком уровне находится российский футбол.
Пример одного из наших исследований:
Ситуация:
Обучаясь на курсах скаутов и общаясь с представителями различных клубов и академий, я неоднократно слышал, что при селекции в детско-юношеском футболе рост игрока имеет самое главное значение. Например, при отборе мальчиков на позиции вратаря, центрального защитника или нападающего, тренеры знакомятся с их родителями, бабушками и дедушками, чтобы понимать, насколько высокими они вырастут.
Проверка гипотезы:
Нам стало интересно проверить гипотезу: действительно ли антропометрия игроков, а именно рост, имеет большое значение для эффективной игры футбольной команды.
Проанализировав данные из открытых источников, мы на цифрах доказали, что в таком подходе к селекции нет абсолютно никакой корреляции между ростом нападающих и количеством забиваемых голов. Также как и между ростом защитников и вратарей и количеством пропускаемых голов. Анализ проводили по молодёжной премьер-лиге (МРПЛ), в которой играют футболисты 2002-2005 года рождения:
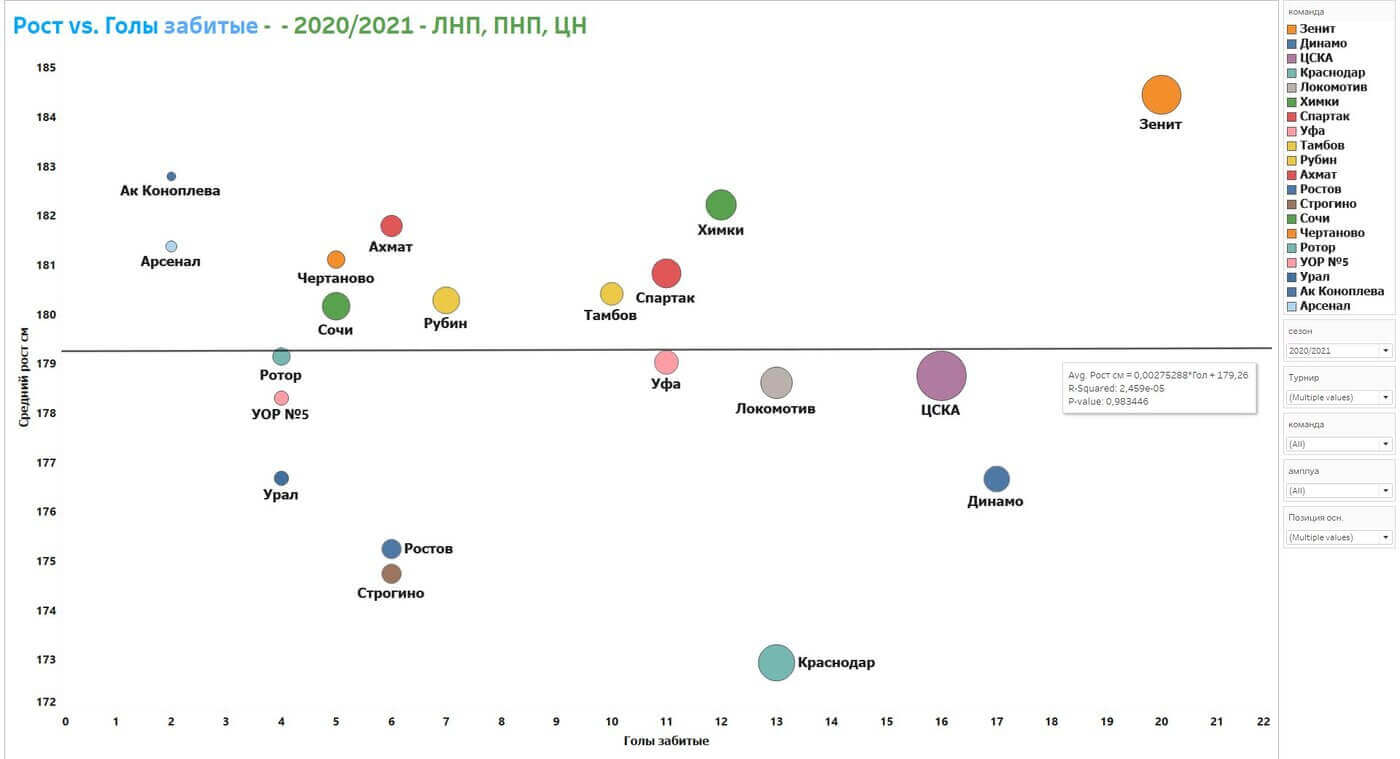
На первом графике из Tableau три оси:
- х – голы забитые командой;
- y – средний рост команды;
- размер ба́бла (bubble) – количество голов, забитых на 1 футболиста команды (метрика эффективности).
Tableau пока не умеет рассчитывать коэффициент корреляции Пирсона, который показывает, есть корреляция или нет, но даёт близкий показатель – R-squared. Если извлечь квадратный корень из R-squared, мы получим коэффициент Пирсона. Поэтому для оценки наличия или отсутствия корреляции достаточно взглянуть на график и проанализировать, как расположены ба́блы и линия тренда. Метрика R-squared, равная практически нулю, сигнализирует о том, что между забитыми центральными нападающими (ЦН), левыми нападающими (ЛНП) и правыми нападающими (ПНП) голами и ростом игроков нет никакой корреляции.
Так, у «Академии Коноплева» игроки группы атаки идут вторыми по среднему росту – около 183 см. По итогам первого круга сезона 20/21 они забили всего 2 гола. А «Динамо», наоборот, имея в составе атакующих игроков со средним ростом 176 см, забили 17 голов, что является вторым местом по результативности.
На следующем графике ищем ответ на вопрос, есть ли смысл иметь в оборонительной линии «гигантов»:
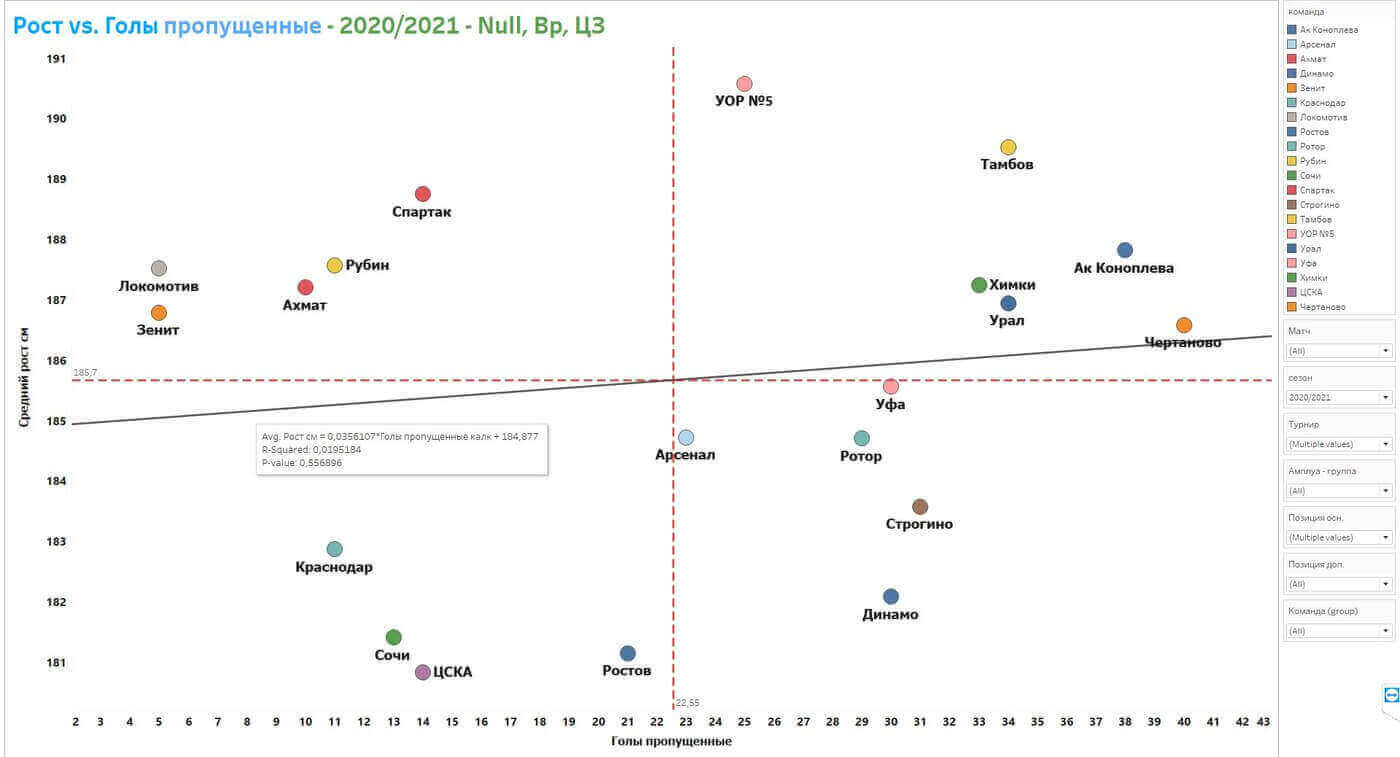
По идее здесь ожидается обратная корреляция: чем выше защитники и вратарь, тем меньше голов они пропускают. Но, судя по графику, такой зависимости тоже нет.
Может показаться, что «Локомотив» и «Зенит», которые пропустили меньше всех (по 5 голов по итогам 1-го круга сезона 20/21) и имеют в составах «оборонцев» со средним ростом 186,5 – 187,5 см, подтверждают наличие зависимости между ростом и количеством пропущенных голов.
Однако смотрим на другие клубы: «Тамбов» (средний рост игроков оборонительной линии – 189,5 см, 35 пропущенных голов), «Академия Коноплева» (средний рост – 187,5 см, 38 пропущенных голов) и «Чертаново» (средний рост – 186,5 см, 40 пропущенных голов). Смотрим также «Краснодар», «Сочи» и «ЦСКА» (средний рост – ниже 183 см, при этом они пропустили менее 15 голов). Так мы получаем R-squared, стремящийся к нулю, и практически горизонтальную линию тренда. Это подтверждает, что погоня тренеров за игроками с определённой антропометрией бессмысленна и рост футболистов не влияет на эффективность игры.
Как стать дата-сайентистом в индустрии футбола
Кирилл Серых:
Чтоб войти в индустрию футбола на позицию дата-сайентиста в первую очередь нужно иметь определённые навыки:
- уметь программировать и визуализировать данные;
- разбираться в алгоритмах и технологиях, которые уже используются в индустрии;
- искать погрешности в данных и придумывать новые / улучшать старые метрики;
- вливаться в футбольное комьюнити и как можно больше показывать свои наработки в анализе футбола.
При этом необязательно иметь профильное образование в программировании или Data Science. Например, я окончил факультет экономики и финансов. Работая в KPMG, я посетил организованную компанией конференцию по технологиям в футболе. Так как мне нравились исследования данных и футбол, я решил перейти из финансов в Data Science в футболе.
Первые полтора года я занимался изучением индустрии. В первую очередь подписался на блог Никиты Васюхина «Блокнот» (аналитик «Рубина», работал в «Зените»), изучал англоязычные сайты по теме и твиттеры иностранных футбольных аналитиков. Живя и работая в Германии, я посещал европейские конференции и футбольные матчи, знакомился с людьми из индустрии. Так на одном из матчей в Голландии мне удалось пообщаться с Леонидом Слуцким, который посоветовал мне закончить тренерские курсы. Сейчас у меня тренерская категория C. Как ассистент тренера я работаю с юношеской немецкой командой U17 в берлинской «Тасмании» – команде Оберлиги (5 немецкая лига).
Опыт тренерства даже на таком уровне помогает лучше понимать, как происходит работа с игроками, как тренировать их с учётом анализа данных и как тренер может смотреть и использовать данные. В этой команде мы не применяем сложные технологии. Я снимаю каждую игру на простую камеру Veo и после отсматриваю тренировки и матчи, делаю нарезки видео, выявляю закономерности, подсчитываю руками очень базовые и простые данные по ударам, пасам, отборам, потерям и формирую рекомендации по улучшению игры футболистов.
Поворотным моментом в карьере дата-сайентиста для меня стало участие в хакатоне, проводимым DFL в 2020-м году, на котором мы с партнёром придумали метрику, позволяющую оценить, насколько правильно действовал вратарь в той или иной ситуации. После этого меня пригласили на должность Football Data Scientist в Sportec Solutions.