 Автор:
Автор: 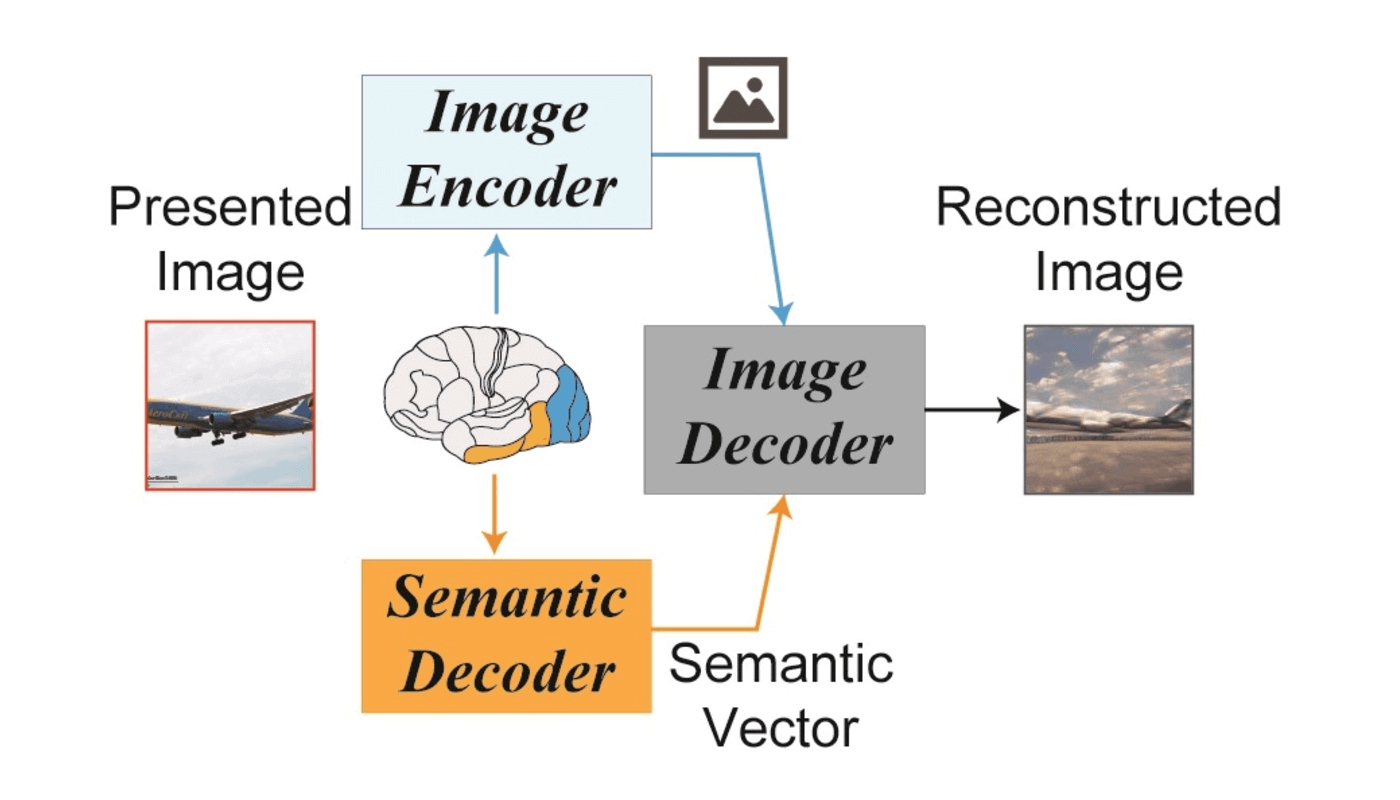
В Университете Осаки разработали нейросеть, способную реконструировать изображение, на которое в данный момент смотрит человек. Анализируя данные функциональной МРТ, система довольно точно воспроизводит не только форму, но и цвета объектов. Учёные заговорили о первой в мире машине для чтения мыслей. Область применения перспективной технологии компьютерного зрения чрезвычайно широка — от коммуникации парализованных людей до записи снов человека и изучения того, как различные животные воспринимают окружающий мир. Исследование опубликовано на bioRxiv.
Японские исследователи воспользовались Stable Diffusion — популярной программой генерации картинок с помощью текста. Эта нейросеть с открытым кодом по структуре не отличается от других генеративных LLM (Large language models, больших языковых моделей), таких как DALL-E от компании OpenAI (создателя чат-бота ChatGPT) или Midjourney. В основе — диффузия, метод машинного обучения, когда визуальный образ формируется посредством последовательного приближения. Каждая новая итерация базируется на очередной текстовой подсказке.
Японцы добавили к стандартной схеме Stable Diffusion дополнительный этап обучения. Нейросеть сопоставляла данные мозговой активности четырёх участников эксперимента, которым демонстрировали разные фотографии с текстовым описанием изображений. В качестве исходных сигналов взяли данные функциональной магнитно-резонансной томографии (фМРТ), полученные на мощных аппаратах с индукцией магнитного поля 7 Тл. Фиксируя потоки молекул кислорода, необходимого нейронам для работы, эти приборы способны отслеживать, какие области мозга, ответственные за те или иные чувства или эмоции, наиболее активны.
На этапе машинного обучения участникам показывали десять тысяч изображений, а система собирала генерируемые при этом паттерны фМРТ, которые затем расшифровывал искусственный интеллект. Часть сканов мозга не использовали — из них потом составили тестовое задание для машины. Проанализировав пики, зафиксированные фМРТ в различных зонах мозга, учёные установили, что височные доли отвечают за содержание изображения. Это так называемая семантическая зона. А затылочная, где зрительная кора, воссоздаёт размер и общее расположение объектов.
Результаты в целом соответствовали гипотезе о двух потоках зрительной информации, сформулированной в 1983-м американским нейропсихологом Мортимером Мишкиным. Он предположил, что в коре головного мозга есть два анатомически и функционально разных канала для обработки пространственной и предметной информации: «Где?» и «Что?». На макаках-резусах Мишкин показал, что затылочный (дорсальный) канал «Где?» отвечает за восприятие пространства, а височный (вентральный) канал «Что?», тесно связанный с памятью, — за узнавание.
Японцы объединили зрительную и семантическую информацию. Алгоритм диффузии сравнивал наблюдаемые паттерны нейронной активности, формирующиеся при просмотре фотографий, с образцами в наборе обучающих данных. По сигналам из «визуальной» зоны коры выстраивались общий объём и перспектива. Затем подключались подсказки с декодера семантических сигналов, и первичная картинка, больше напоминающая помехи на экране телевизора, постепенно приобретала очертания узнаваемых объектов.
Учёные получили около тысячи картинок, и они с точностью до 80 процентов совпали по смыслу и содержанию с оригиналом. В большинстве случаев искусственный интеллект даже воссоздал цветовую гамму исходного изображения. Представленная статья продемонстрировала, что нейросеть Stable Diffusion может точно реконструировать изображения из сканирования фМРТ, и это позволяет эффективно читать мысли людей.
«Мы показываем, что наш метод на основе активности человеческого мозга способен реконструировать изображения с достаточным разрешением и высокой семантической точностью», — уточняют сами исследователи.
Авторы работы подчеркивают, что предложенная ими модель — универсальная, не нуждающаяся в тонкой индивидуальной подстройке к мозгу конкретного человека. Алгоритм интерпретирует не только активность в «визуальной» коре, отвечающей за восприятие формы и цвета, но и процессы в соседней «семантической» зоне головного мозга, где зрительная кора встречается со слуховой и где закодированы значения слов.
Однако пока в качестве тестовых образцов использовали сканы мозговой активности тех же самых четырёх участников эксперимента, на которых машина обучалась. То есть семантический декодер был настроен на распознавание конкретных заученных заранее сигналов. Кроме того, испытуемые были активно настроены на эксперимент. Пока фМРТ визуализировала их мозг, они мысленно «проговаривали» картинку, описывая словами всё, что видят. Для машины это были дополнительные подсказки.


