Автор:
Автор: 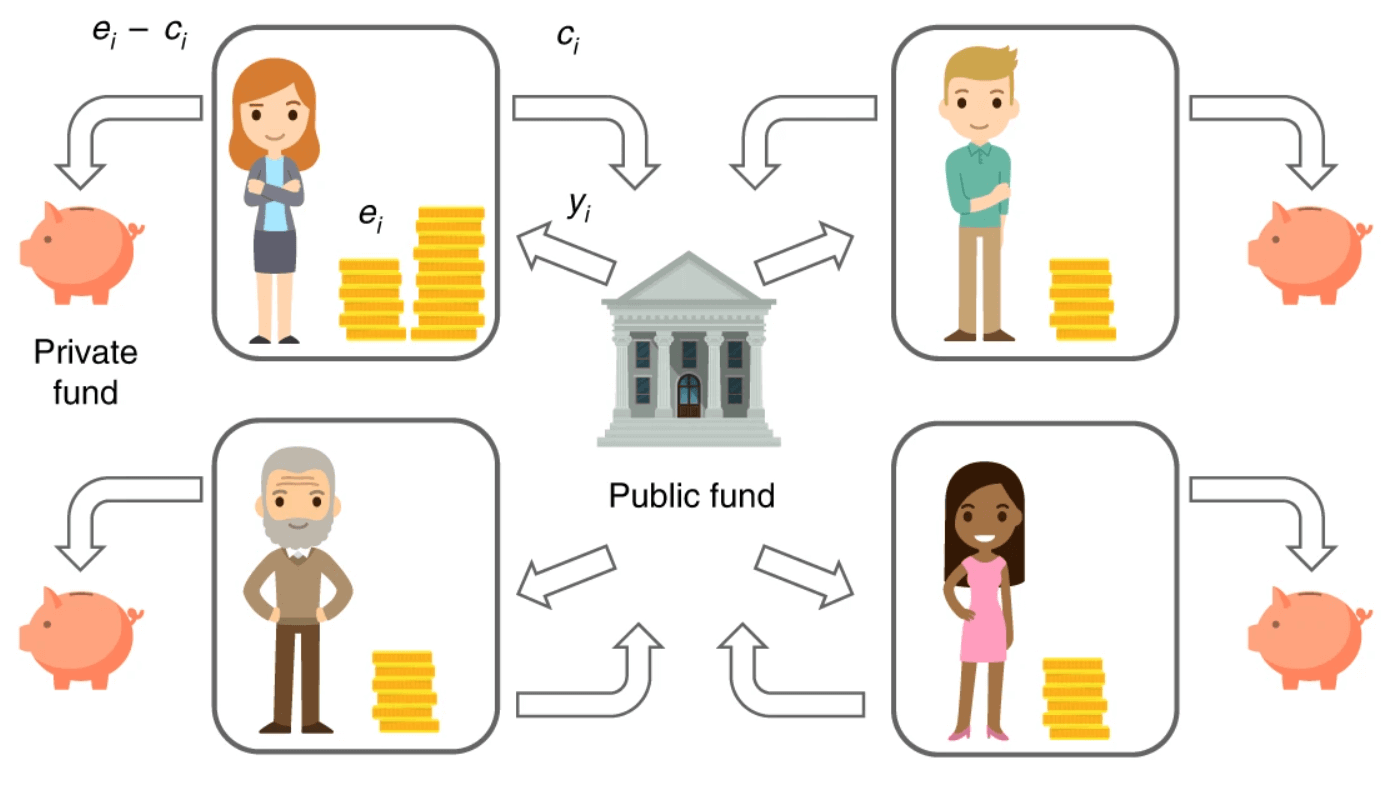
Британские исследователи разработали алгоритм машинного обучения, который учится распределять средства между людьми наиболее предпочтительным для них образом. Во время экспериментов люди вкладывали деньги в общее дело, а распределение заработанных средств зависело от применяемой политики: простого правила, например, выплата соразмерно вложенным средствам, модели машинного обучения или человека. Опросы показали, что модели удалось выучить политику, которую люди предпочли остальным вариантам. В частности, она учитывала то, какую долю от своих средств вкладывал человек, а также старалась снижать выгоду тех, кто почти ничего не вкладывал. Статья опубликована в журнале Nature Human Behaviour.
Машинное обучение в основном применяется в сферах и задачах, где ясно, как именно должен поступать алгоритм. Самый простой пример — классификация изображений животных, при которой алгоритм просто должен корректно отличать кошек от собак и других существ. Есть и более сложные задачи, такие как написание текстов, в которых помимо объективных метрик также важна субъективная оценка людей и здравый смысл. Но существуют и области, в которых ни у научного сообщества, ни у обычных людей нет единого ответа на вопрос о том, как должен работать алгоритм. К примеру, существуют разные экономические школы, предлагающие обществу разные экономические модели. И при наличии у общества демократических механизмов применяемая экономическая политика представляет собой компромисс между людьми с разными предпочтениями.
Исследователи из компании DeepMind и Эксетерского университета под руководством Кристофера Саммерфилда (Christopher Summerfield) разработали алгоритм, который по сути реализует на практике демократический механизм выбора экономической политики, лучшим образом отражающей предпочтения общества. Авторы использовали в своей работе простую экономическую игру, в которой люди получали средства, вкладывали их по своему усмотрению в общее дело и получали прибыль, распределение которой по людям варьировалось в зависимости от применяемой политики.
Эксперимент был построен следующим образом. Группа игроков состояла из четырёх добровольцев. В начале игры каждый игрок получал монеты: один из них получал 10, другие — от 2 до 10. Каждый игрок мог вложить произвольную сумму (в пределах доступного количества монет) в общий фонд, который увеличивал средства на 60 процентов. После этого средства распределялись согласно применяемой политике распределения и процесс повторялся заново в течение 10 раундов (за исключением раздачи первоначальных средств, которое происходило только перед первым раундом).
Исследователи провели четыре вида экспериментов, построенных по такой методике. В первом, в котором участвовало 756 человек, прибыль распределялась по одному из трёх простых механизмов:
- Эгалиратрный, при котором прибыль распределяется равным образом, вне зависимости от того, кто сколько вложил.
- Либертарианский, при котором прибыль распределяется соразмерно вложениям.
- Либертарно-эгалитарный, при котором прибыль распределяется в зависимости от того, какую долю от своих накоплений вложил каждый игрок.
Во втором эксперименте авторы обучили нейросетевых агентов на базе рекуррентной нейросети, которые учились имитировать поведение людей. Это позволило значительно увеличить масштаб игр, не привлекая множество добровольцев, что довольно затратно. Затем исследователи обучили с помощью этих имитирующих агентов нейросетевую модель. Для этого агенты голосовали за модель на основании её распределений, за счёт чего она обучалась наиболее популярной политике. После обучения авторы провели эксперименты с людьми (2508 участников), в которых в первые 10 раундов распределение было через один из обычных механизмов, а во вторые 10 — через нейросеть. Выяснилось, что люди предпочитают нейросетевую политику распределения средств всем трём стандартным: 66,2 процента против эгалитарного распределения, 60,8 процента против либертарианского и 54,5 против либертарно-эгалитарного.
В третьем эксперименте авторы вообще отказались от данных людей и обучили алгоритм-агент максимизировать свою прибыль, а затем обучили на этих агентах соответствующую политику. В эксперименте участвовало 736 человек и большинство (57,2 процента) предпочло нейросетевую политику, обученную на данных людей. В четвёртом эксперименте авторы пригласили 61 уже игравшего человека и предложили им распределять средства участников эксперимента. Обучившись на имитирующих агентах, они приступили к эксперименту с 244 реальными людьми. И снова игроки предпочли нейросетевую политику (62,4 процента).
Исследователи отмечают, что нейросетевому алгоритму, обученному на данных людей, удалось выработать политику распределения средств, отчасти похожую на либертарно-эгалитарную. В частности, он отдавал предпочтение людям, вкладывавшим примерно половину своего состояния. Кроме того, он был более выгодным для тех, кто начинал игру с небольшим состоянием. Авторы отмечают, что в третьем эксперименте исходили из предположения, что участники — полностью рациональные агенты, стремящиеся максимизировать прибыль. Однако на самом деле предсказание экономического поведения людей — крайне сложная область экономики, за исследование в которой в 2017 году присудили Нобелевскую премию.