 Автор:
Автор: 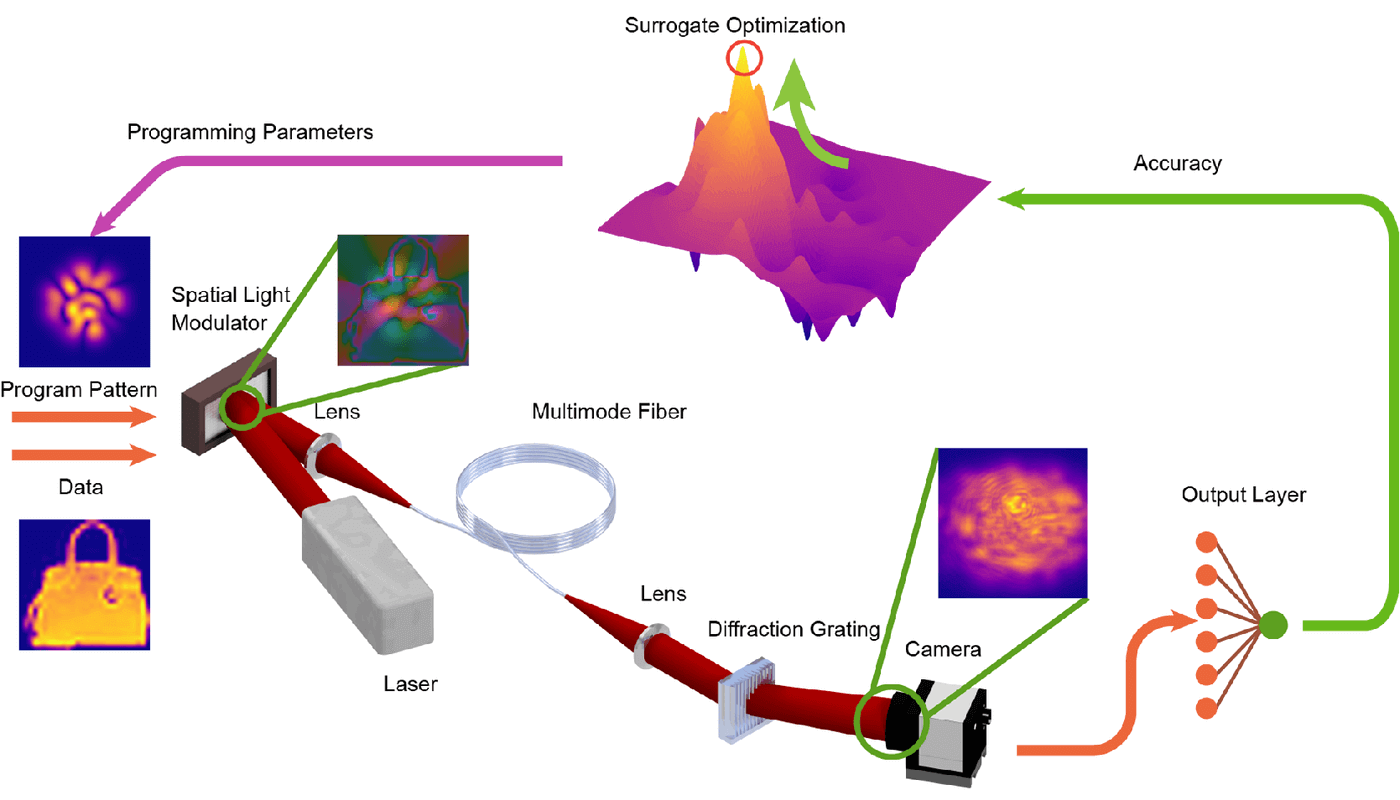
Современные генеративные модели искусственного интеллекта используют сотни миллиардов параметров для решения всё более сложных задач. Обучение нейросетей таких масштабов требует огромных вычислительных мощностей, которые могут быть предоставлены только центрами обработки данных величиной с ангар, потребляющими энергию, эквивалентную потребностям в электричестве среднего по размеру города. Например, на обучение языковой модели GPT-3, которая имеет 175 миллиардов параметров, было потрачено 1,3 гигаватт-часа электроэнергии, что достаточно для полной зарядки 13 тысяч автомобилей Tesla.
Для устойчивого развития искусственного интеллекта в его нынешнем темпе возникает необходимость переосмыслить как сами алгоритмы машинного обучения, так и требующееся для них вычислительное оборудование. Одним из решений может стать оптическая аппаратная реализация архитектуры нейронных сетей, то есть переход от опоры на чисто транзисторные вычислительные мощности к системам на оптоволоконной основе. В новом исследовании, опубликованном в журнале Advanced Photonics, группа учёных разработала такую нейросеть.
Предложенная архитектура сочетает в себе оптическую составляющую с небольшим количеством программируемых в цифровом виде параметров. С помощью метода, известного как формирование волнового фронта, исследователи управляли ультракороткими импульсами в многомодовых волокнах — это волокна с большим диаметром сердцевины, проводящие лучи света благодаря эффекту полного внутреннего отражения. Такие оптические волокна поддерживают несколько поперечных мод для заданной оптической частоты и поляризации. С их помощью учёные осуществляли нелинейно-оптические вычисления со средней оптической мощностью, измеряемой всего в микроваттах.
В результате производительность для задачи классификации изображений была сопоставима с цифровыми системами на транзисторной основе, имеющими в 100 с лишним раз большее количество параметров при одинаковом уровне точности. Учёные уменьшили количество параметров модели на 97 процентов, что привело к общему сокращению цифровых операций на 99 процентов по сравнению с аналогичной цифровой многослойной нейронной сетью, основанной на чисто транзисторной аппаратной части. Например, система приблизительно с двумя тысячами параметров работала так же хорошо, как типичная цифровая нейронная сеть более чем с 400 тысячами параметров.
Отдельно авторы рассмотрели вопрос скорости вычислений их нейросети, которая определяет итоговую скорость получения выводов от модели. Для их варианта сети она невысока и ограничена частотой обновления жидкокристаллического пространственного модулятора света. Это ограничение можно преодолеть, перейдя на более быстрый метод формирования волнового фронта: например, если использовать коммерческие цифровые микрозеркальные устройства и квадрантные фотодиоды — это фотодиоды, которые состоят из четырех оптически активных зон (излучающие диоды), разделённые между собой небольшим промежутком (их обычно используют для определения положения лазерных лучей друг относительно друга).
Реализуя ту же архитектуру оптических вычислений с набором коммерчески доступного высокоскоростного оборудования, можно было бы достичь производительности 25 терафлопс при общем энергопотреблении 12,6 ватта, что значительно ниже, чем потребление в 300 ватт классическим транзисторным графическим процессором с сопоставимой производительностью. Обращает на себя внимание огромный разрыв в возможностях нейросетей на оптической элементной базе и на классической транзисторной. Если его удастся перенести в серийные коммерческие решения, то именно первые, по всей видимости, станут будущим в развитии больших языковых моделей, подобных GPT-4.


